”Deduplication Rules” Table
The Deduplication Rules Table defines how alerts are grouped into cases based on specific criteria. These rules are crucial in ensuring that related alerts are aggregated into the same case, reducing duplication and improving case management efficiency.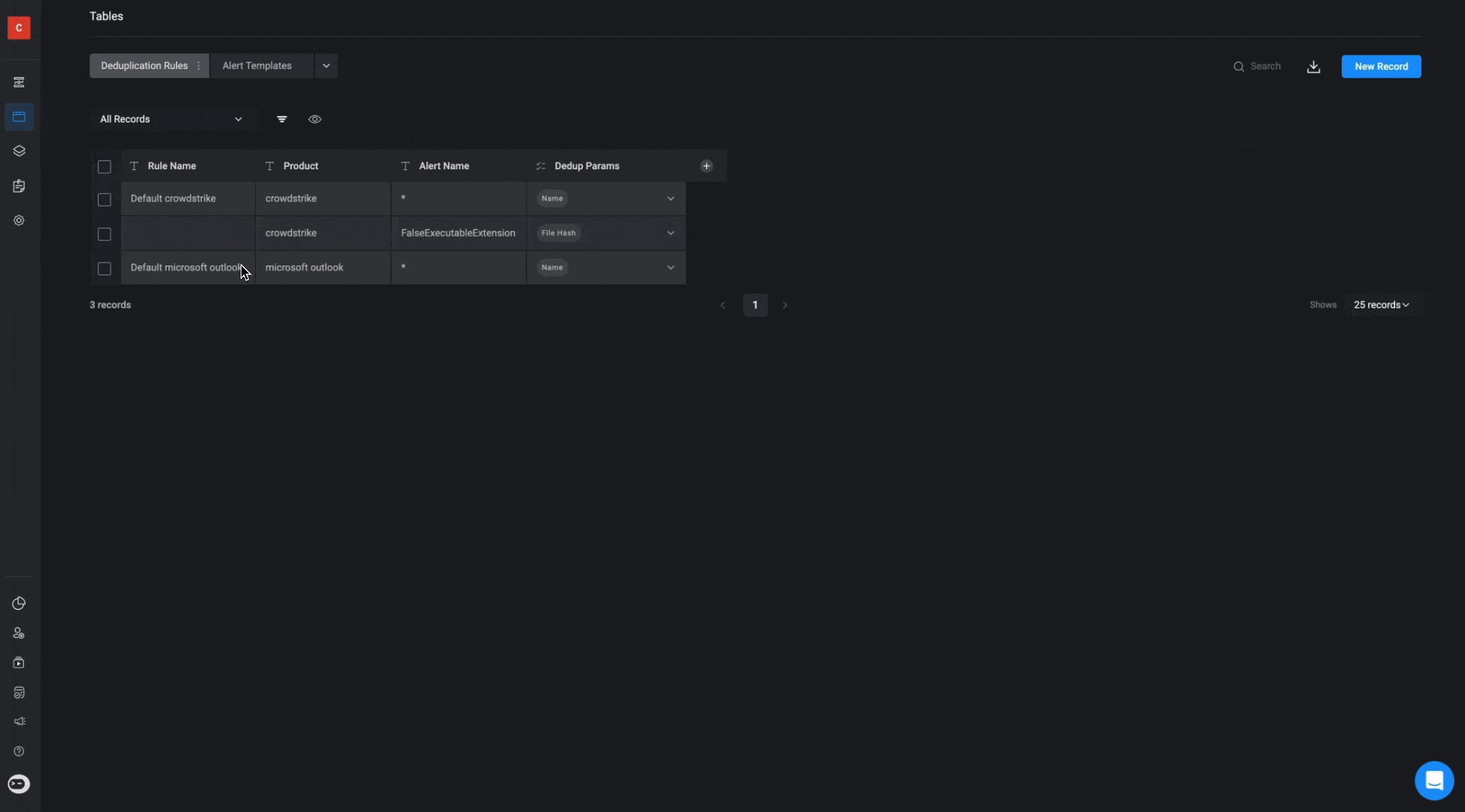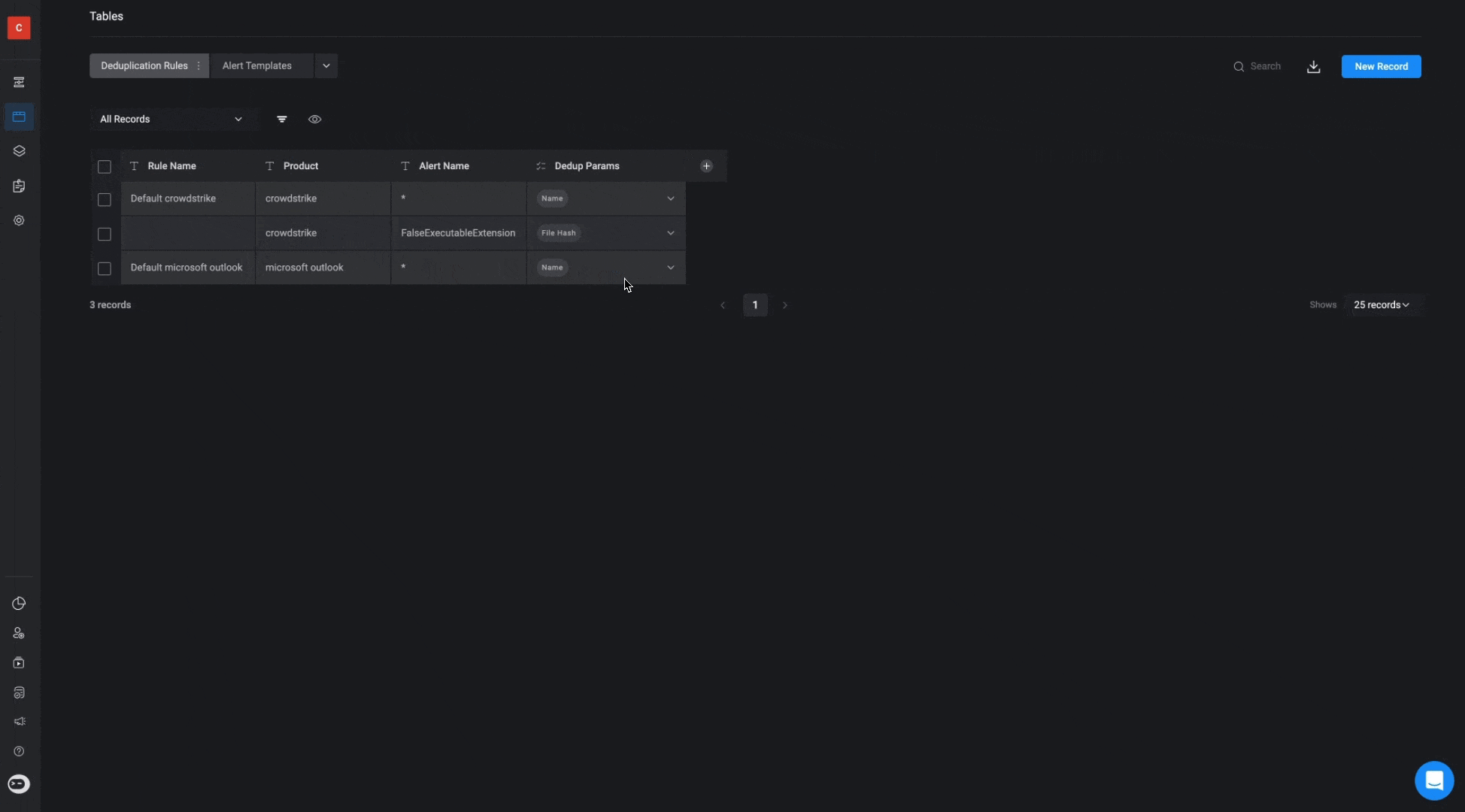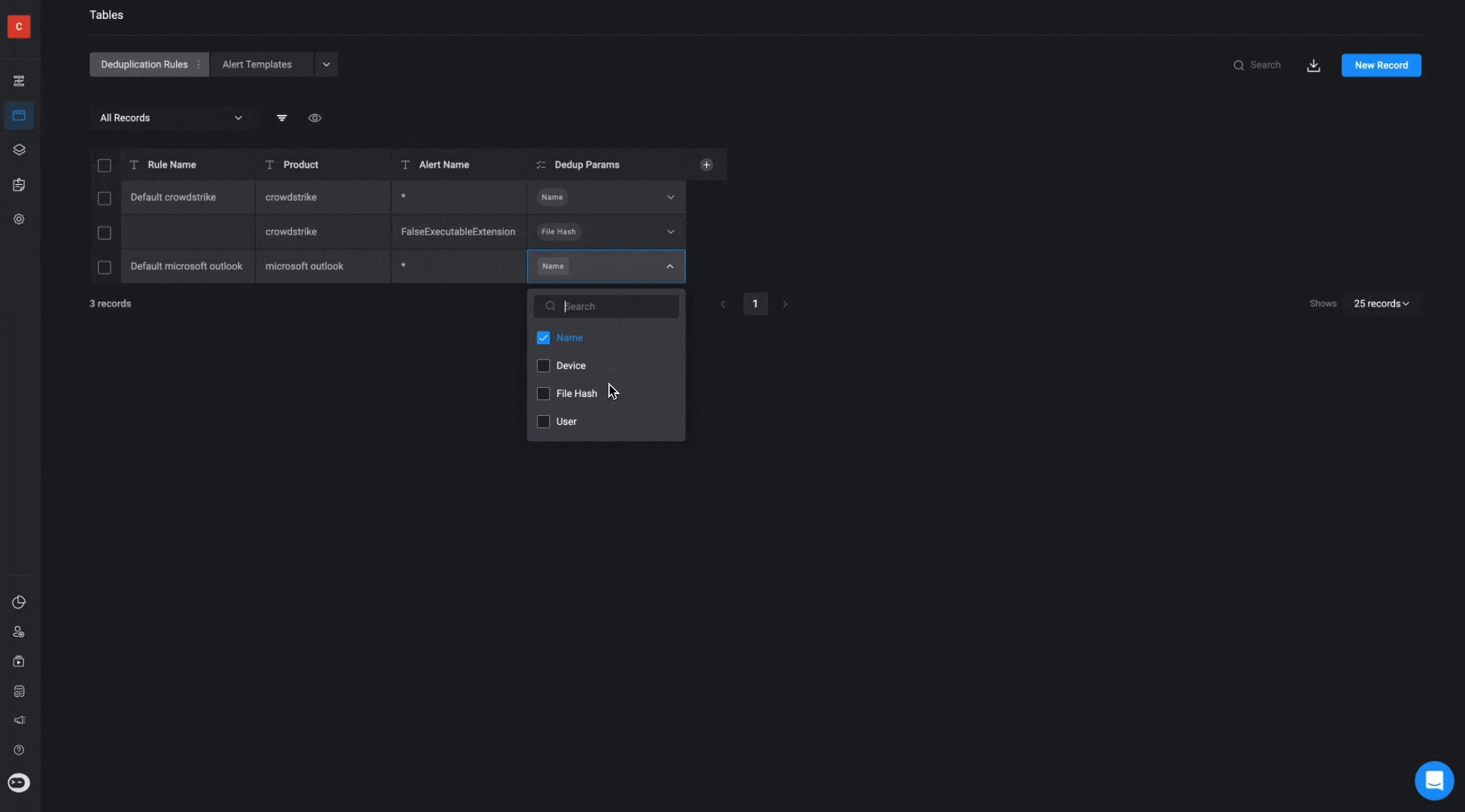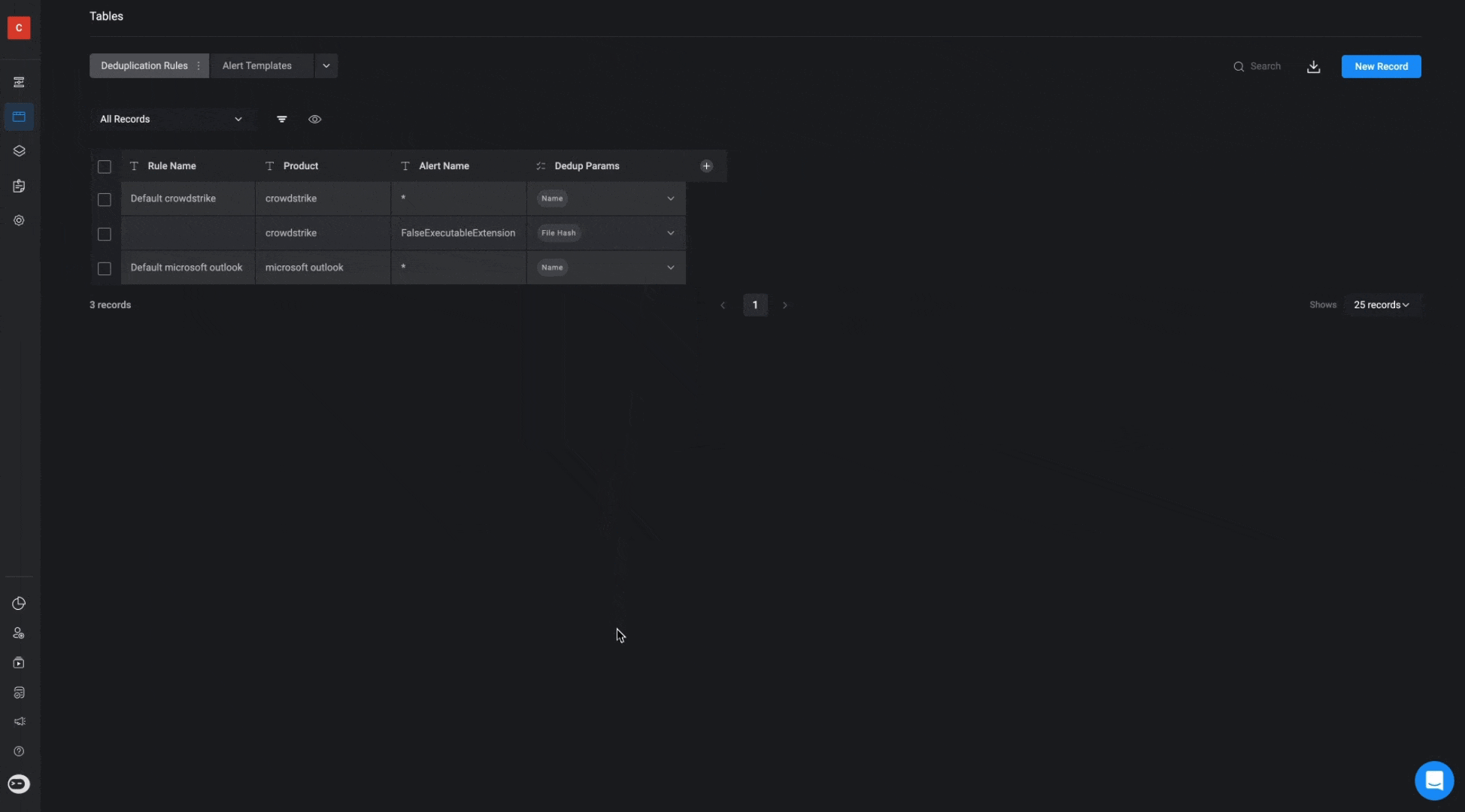
-
Automatic Universal Rule Creation
- If a specific deduplication rule is not present for an alert, a universal rule is automatically created. This universal rule defaults to deduplicating alerts based on the alert name, ensuring alerts with similar names are grouped together.
-
Customizable Deduplication Rules
- These rules provide flexibility for customers to customize how alerts are deduplicated without needing to alter the core workflows. This ensures that deduplication aligns with customer-specific requirements and processes.
-
Wildcard Support
- The alert name field supports the
%symbol as a wildcard. This allows broader matching of alerts that may have similar names but slight variations, ensuring they are still deduplicated into the same case.
- The alert name field supports the
-
Deduplication Parameters
- Alerts can be deduplicated based on several key parameters, depending on the needs of the organization. The parameters available for deduplication include:
- Alert Name: Groups alerts based on similar or identical names.
- User: Groups alerts that are associated with the same user.
- Device: Groups alerts related to the same device.
- IOC Type: Deduplicates based on the type of Indicator of Compromise (IOC), such as Hash, IP Address, or other IOC types.
- Alerts can be deduplicated based on several key parameters, depending on the needs of the organization. The parameters available for deduplication include:
-
Case Handling
- Alerts can be aggregated into an already open case or, if no open case is found, into a case that was closed within the last 7 days (the case will be reopened). If no matching case exists, a new case will be created to handle the alert.
”Main- Case Processing” Subflow
The purpose of the Case Processing Workflow is to efficiently manage alerts by identifying duplicates and linking them to existing cases or creating new ones when needed. It uses predefined deduplication rules to check for duplicate alerts, ensures that relevant cases are reopened if necessary, and links alerts and observables to the appropriate cases. This workflow streamlines case management, ensuring that redundant cases are avoided and all related alerts are properly associated.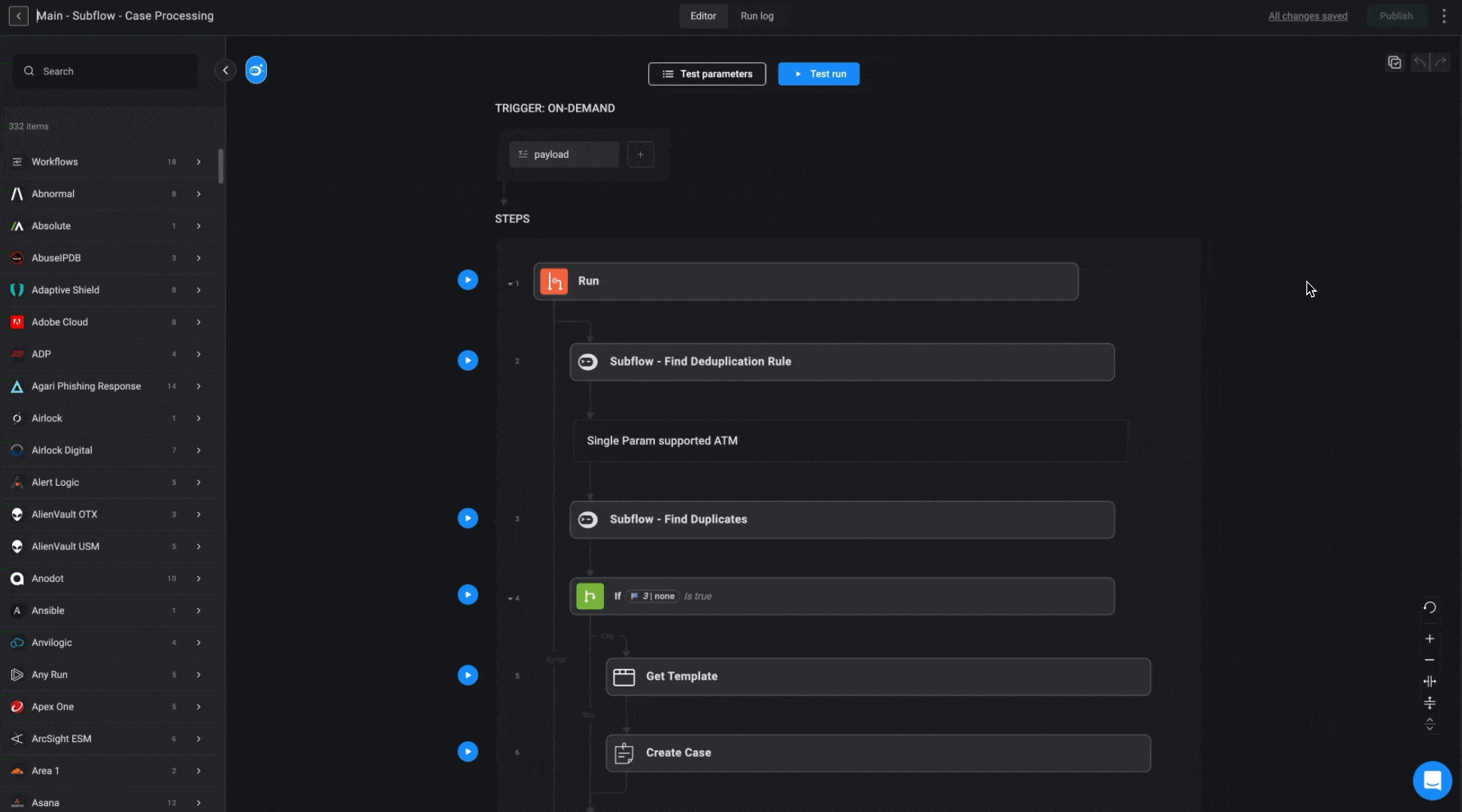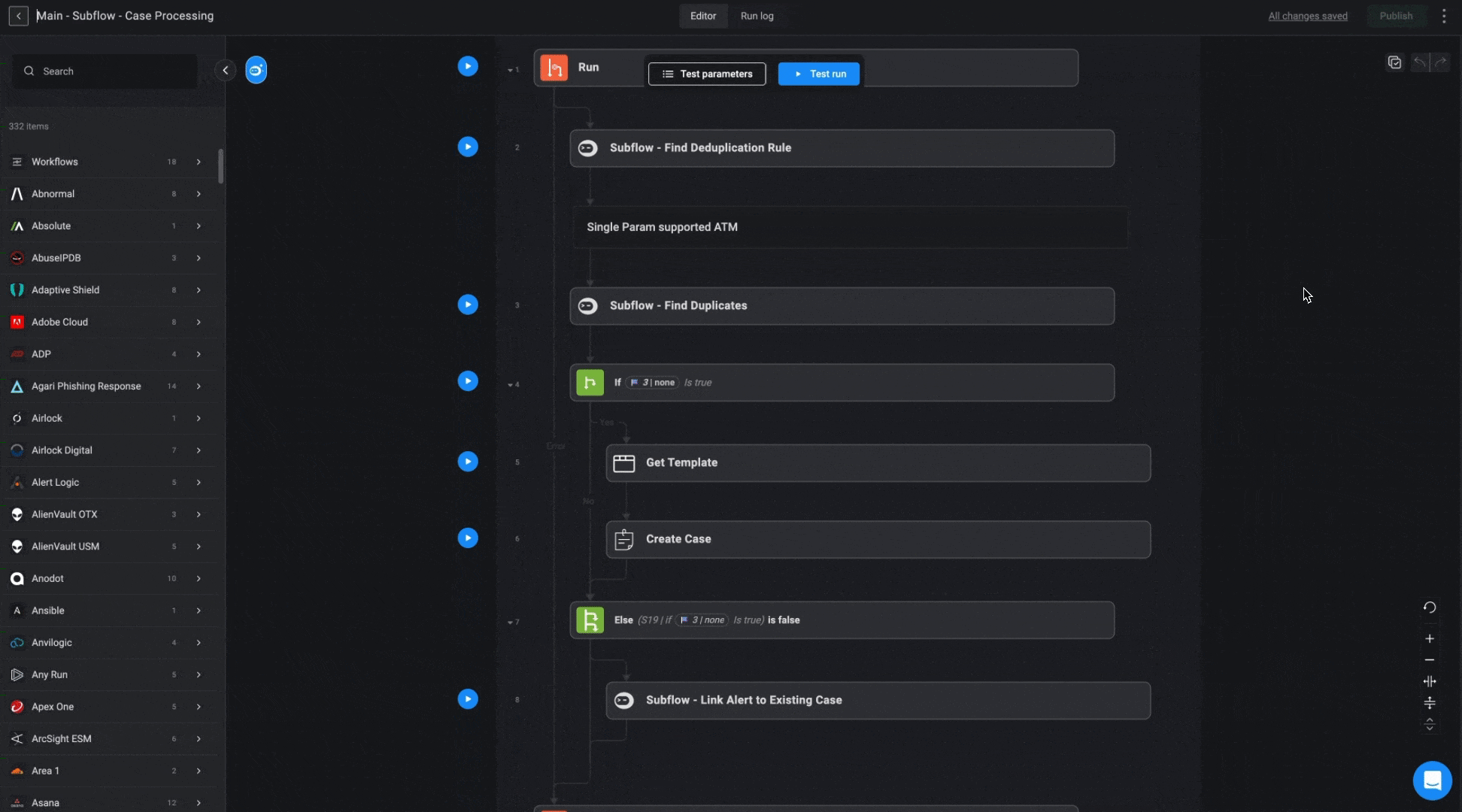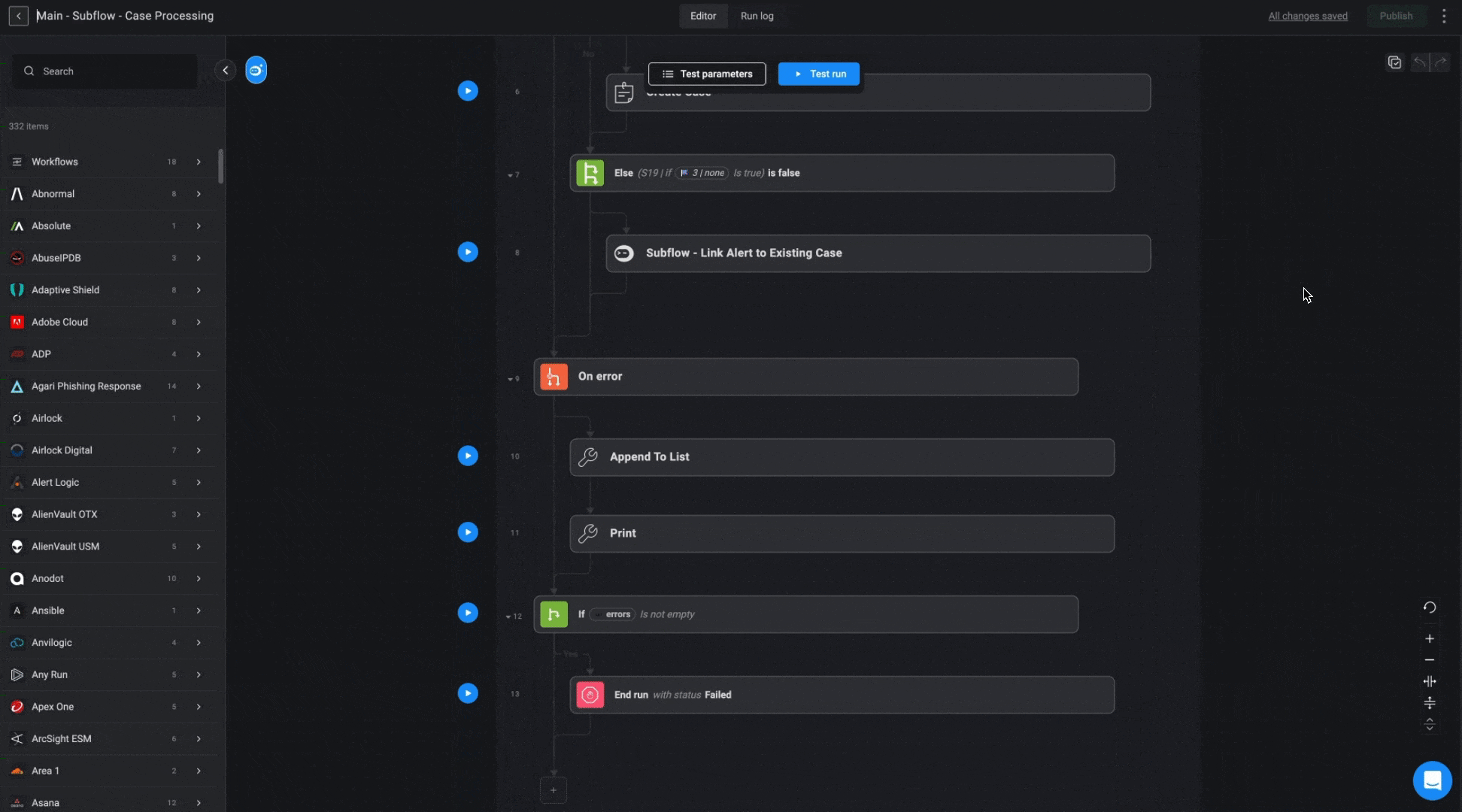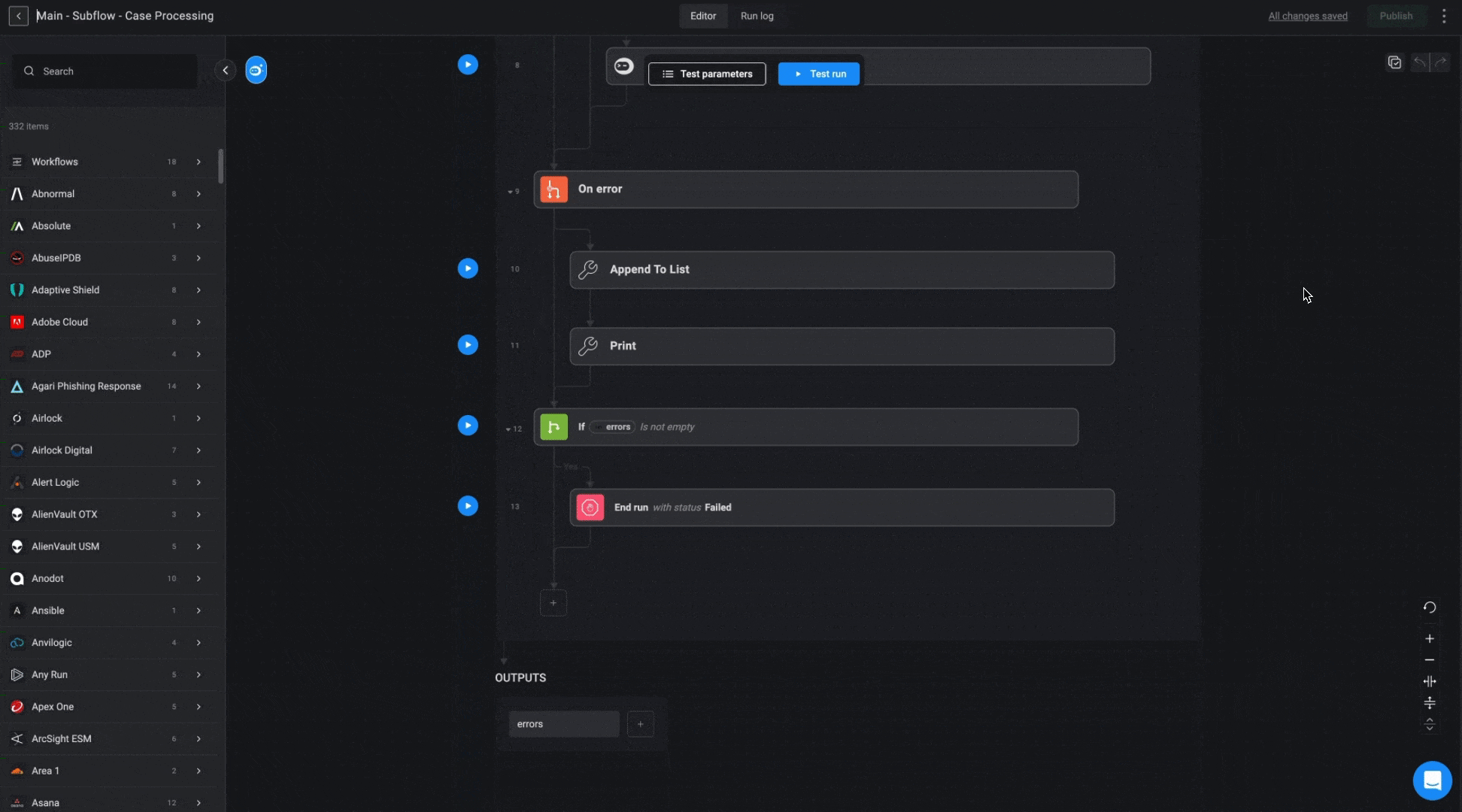
”Subflow- Get Duplication Rule” Workflow
This Subflow determines the most suitable deduplication rule for a given alert, following a hierarchy of priority. It first checks for a specific rule associated with the alert. If no specific rule is found, it attempts to retrieve a universal rule for the vendor. If no universal rule exists, one will be created using “Name” as the default deduplication parameter.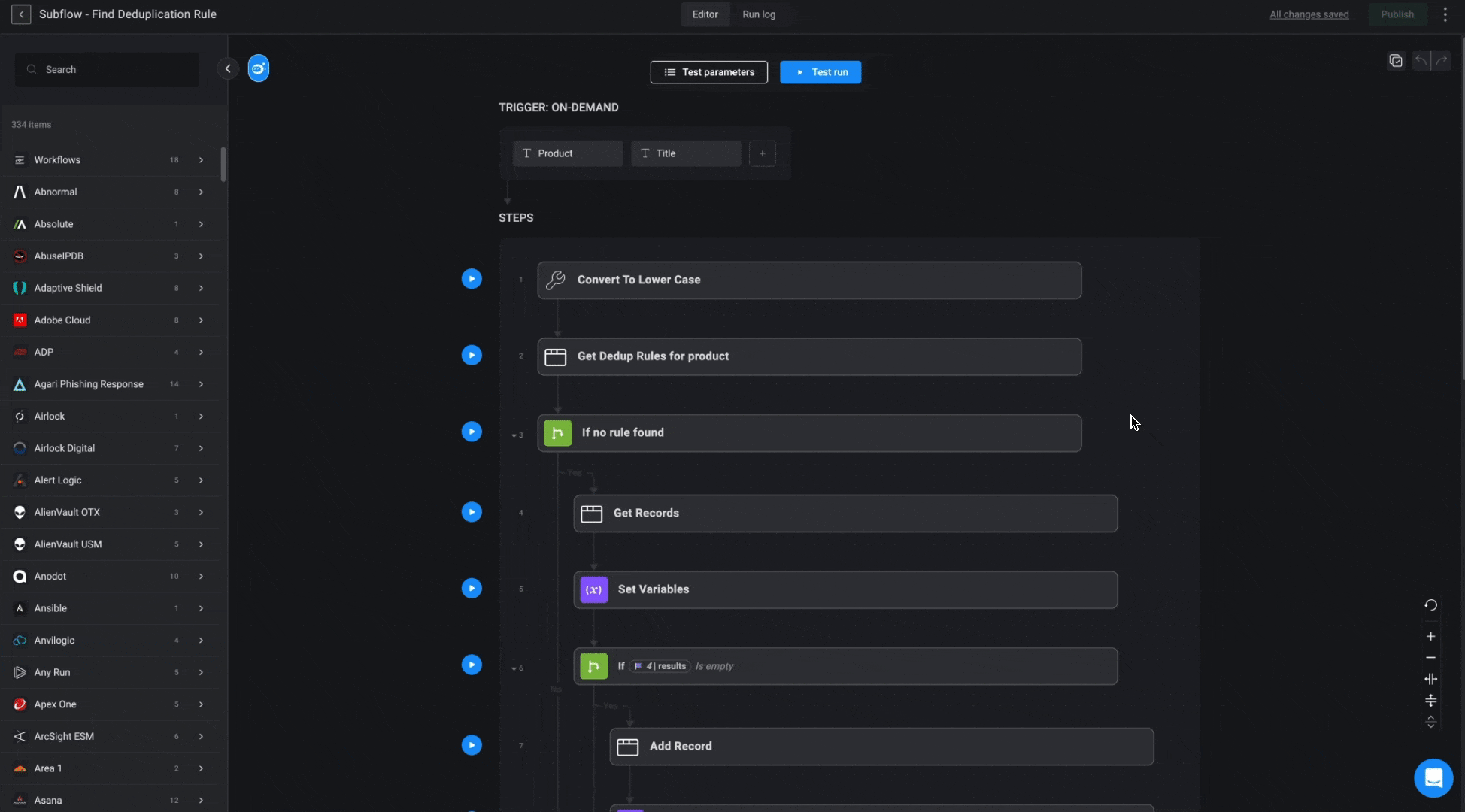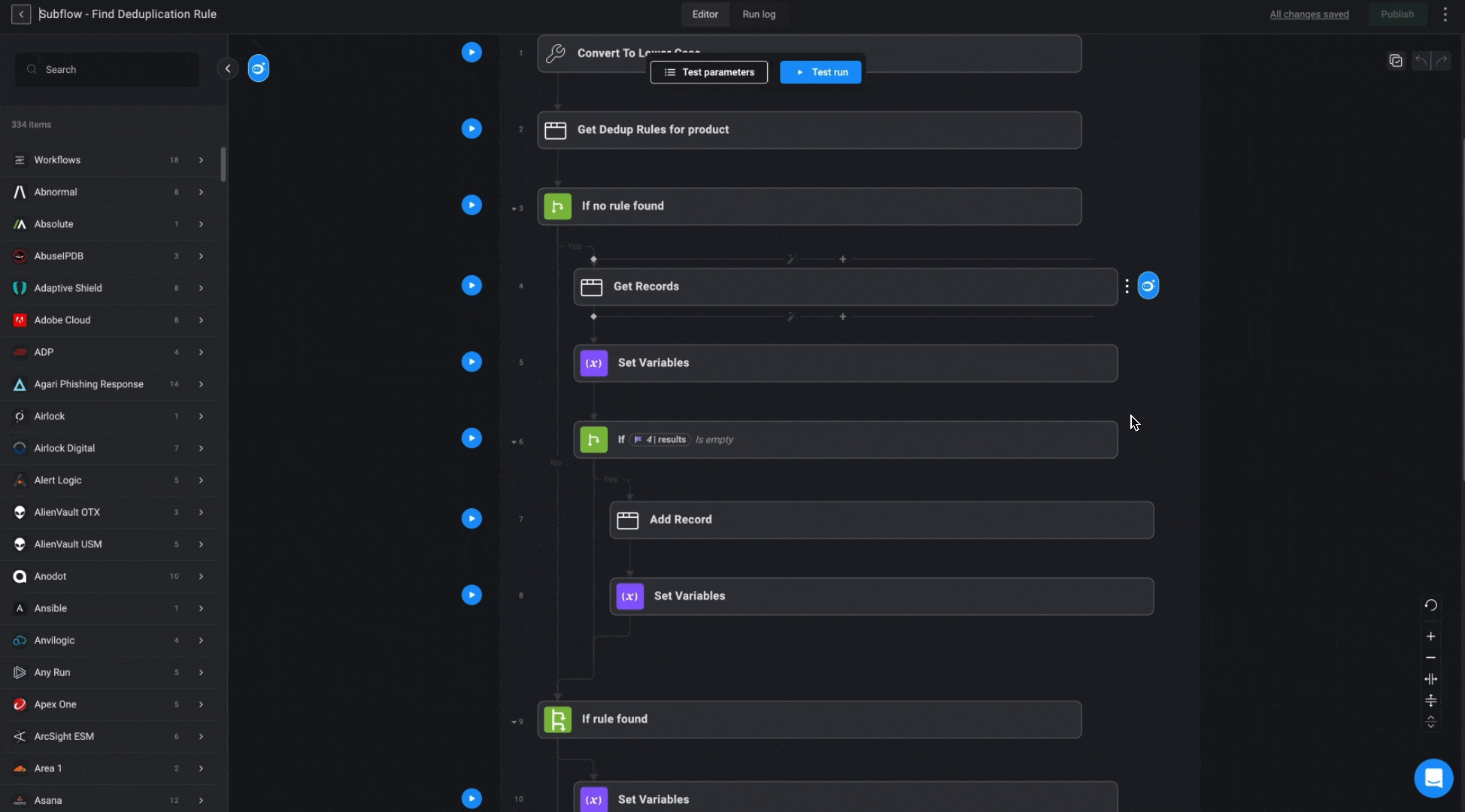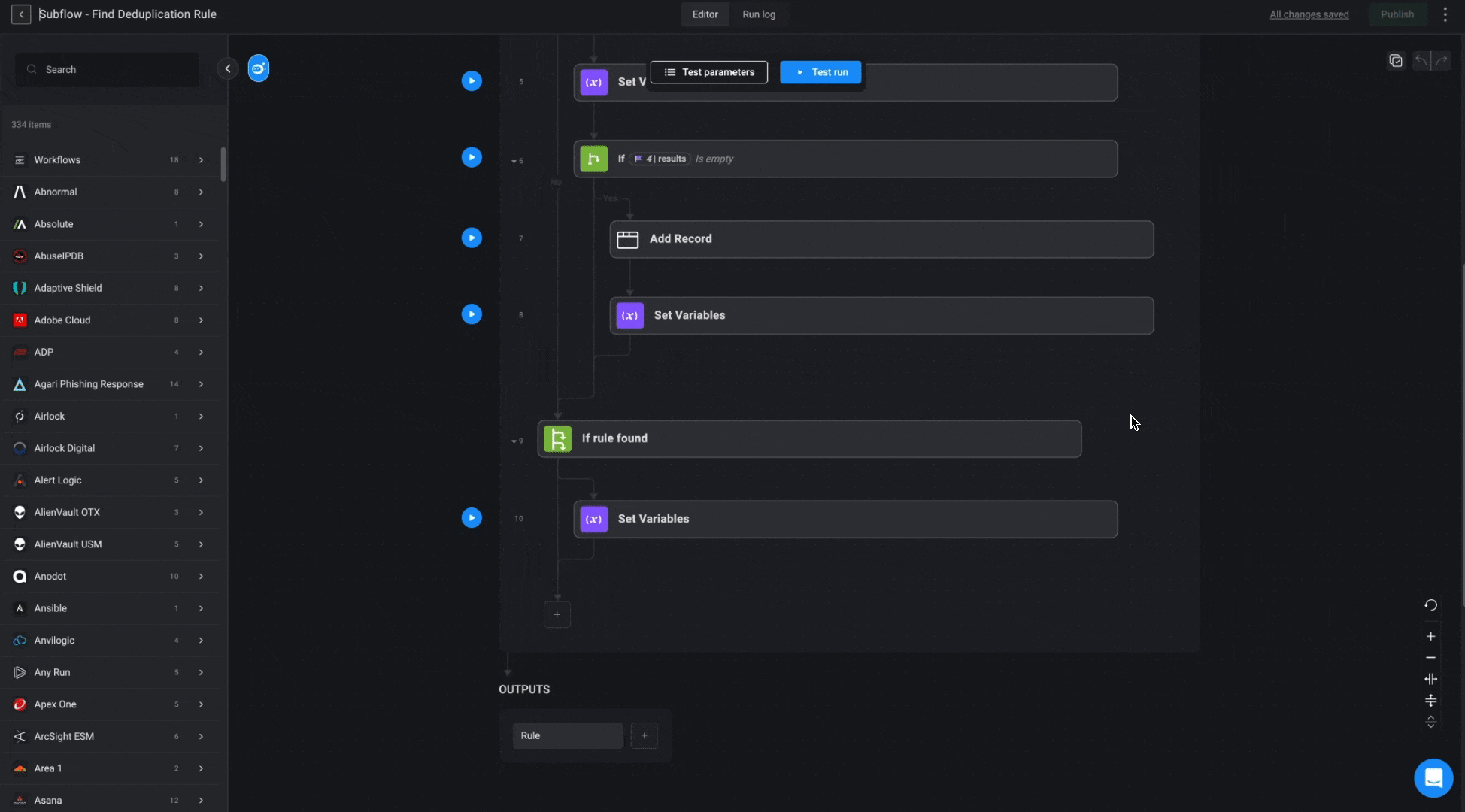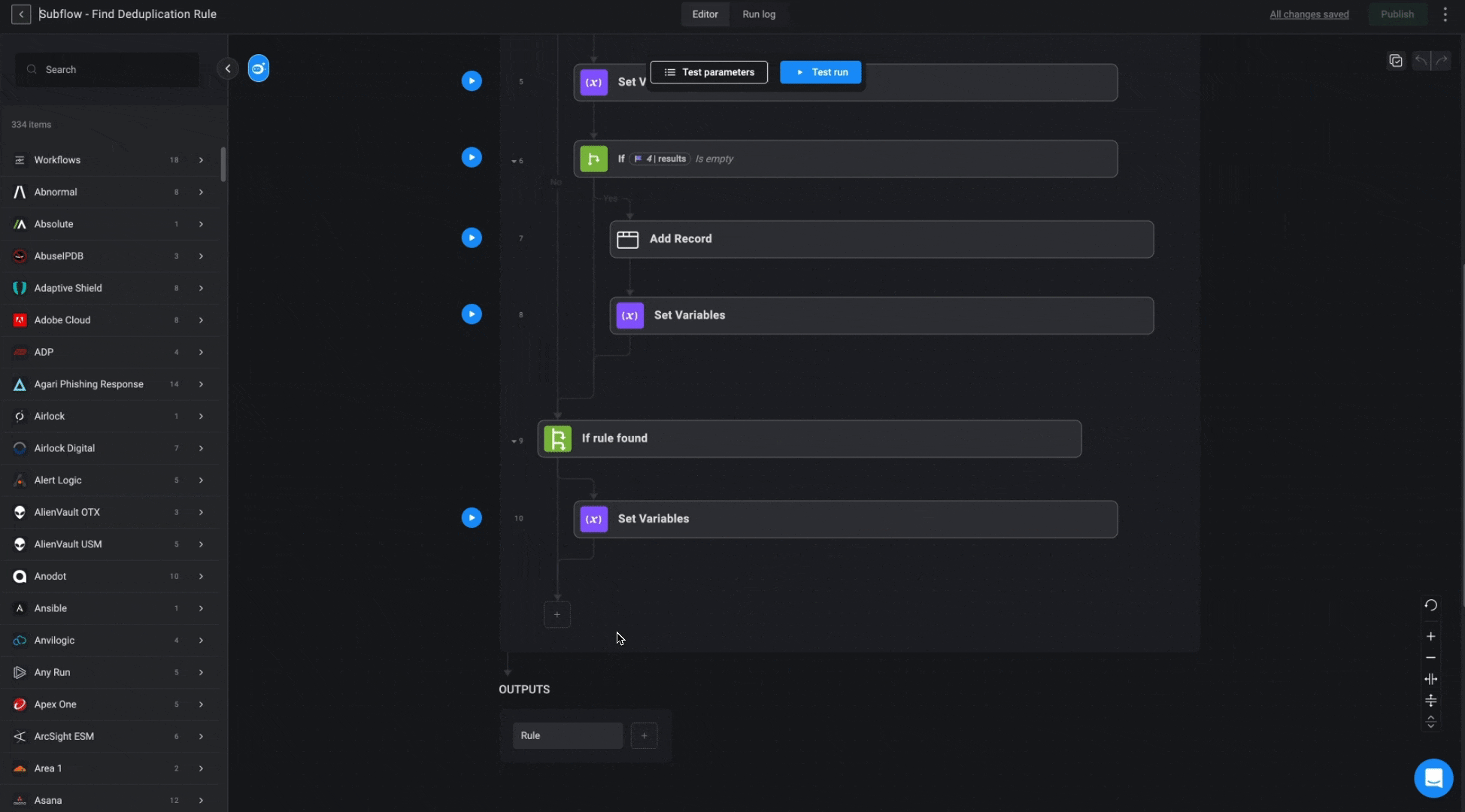
”Find Duplicates” Subflow
This subflow identifies if the alert has any duplicates in any open case or in a case closed within the last 7 days. If duplicates are found, it provides the case ID, flags whether the case should be reopened, and if no duplicate exists.- If multiple observables are valid for deduplication (e.g., the deduplication parameter is “User” and multiple users are linked), the first case found will be used. If there are multiple cases, the most recently updated one will be selected.
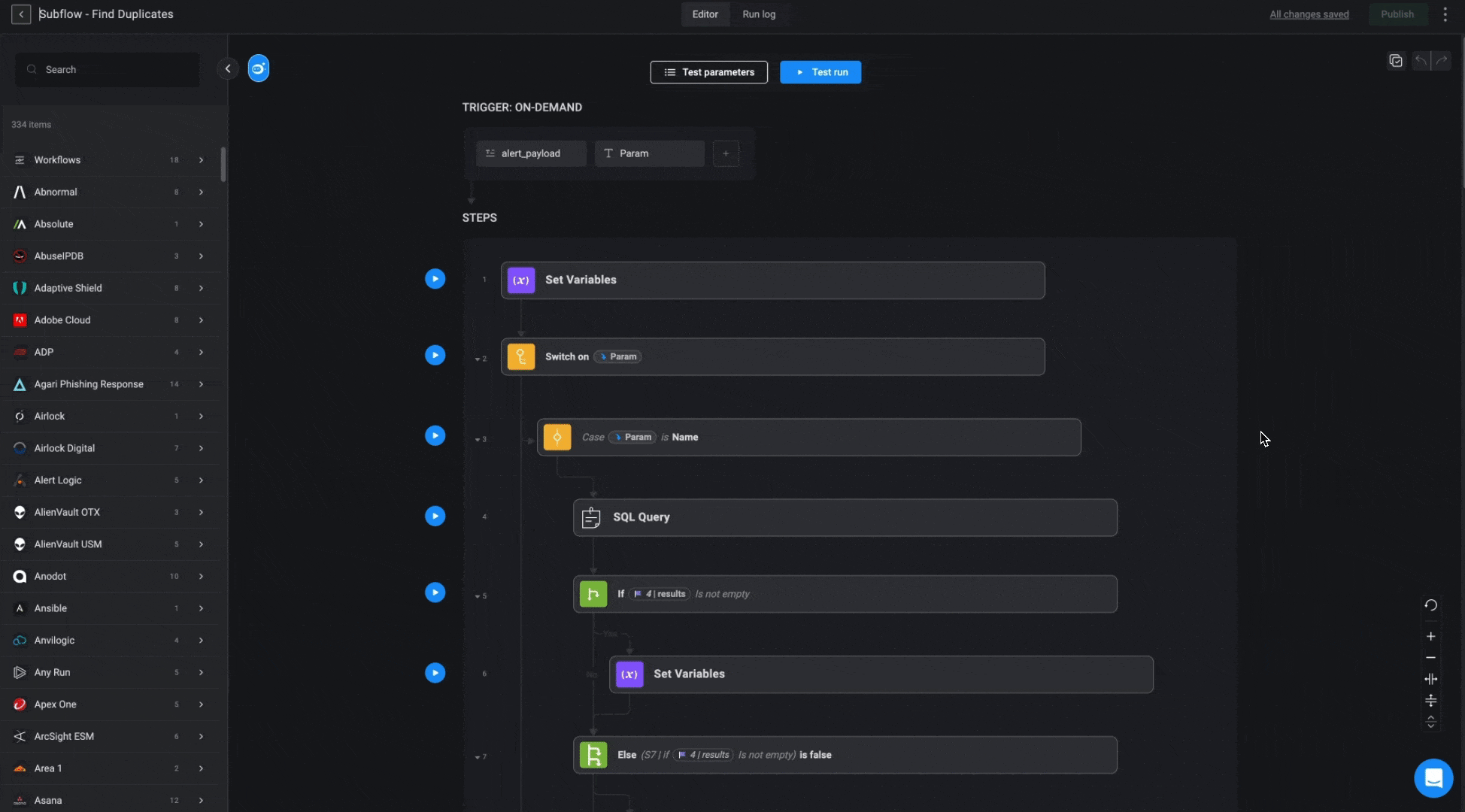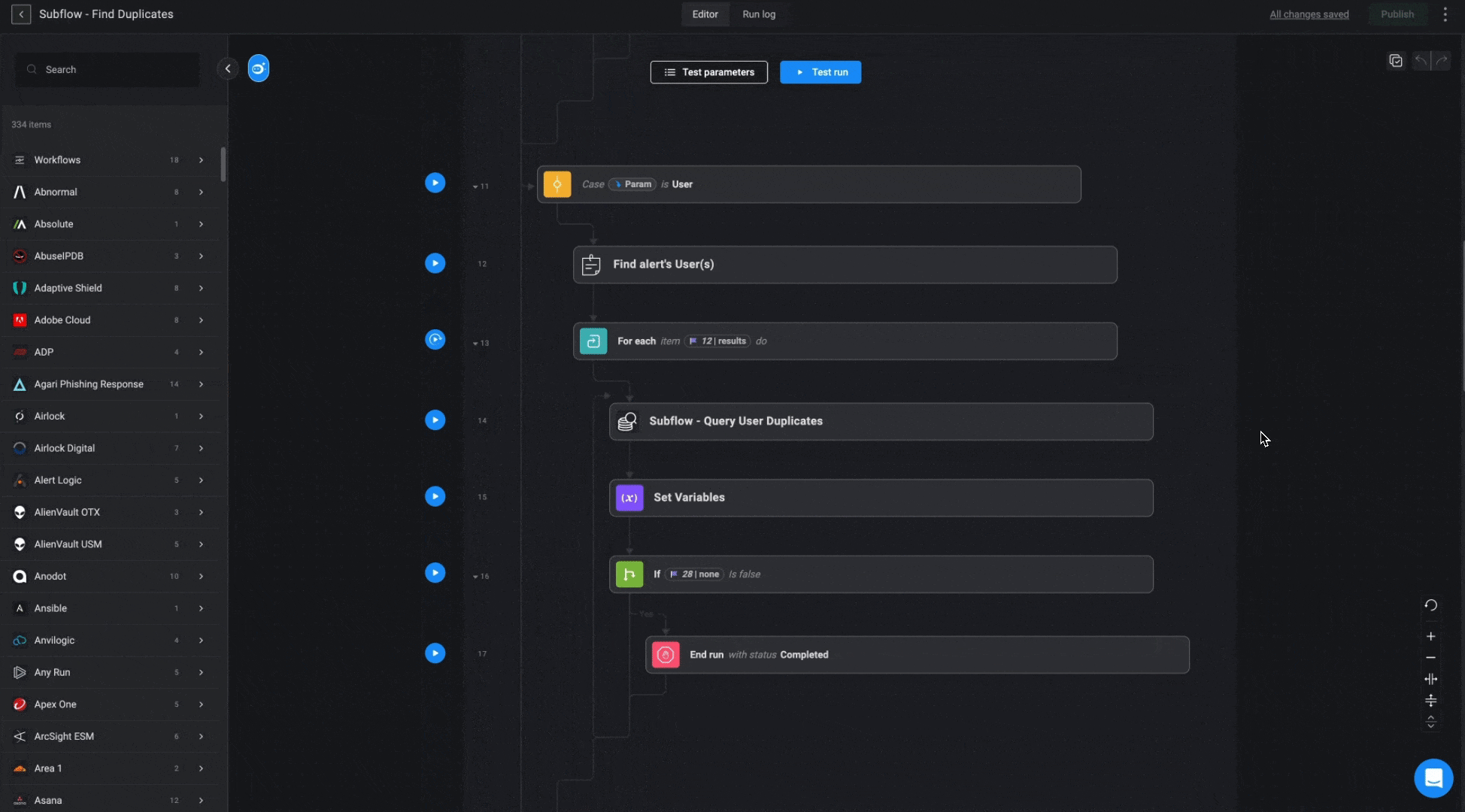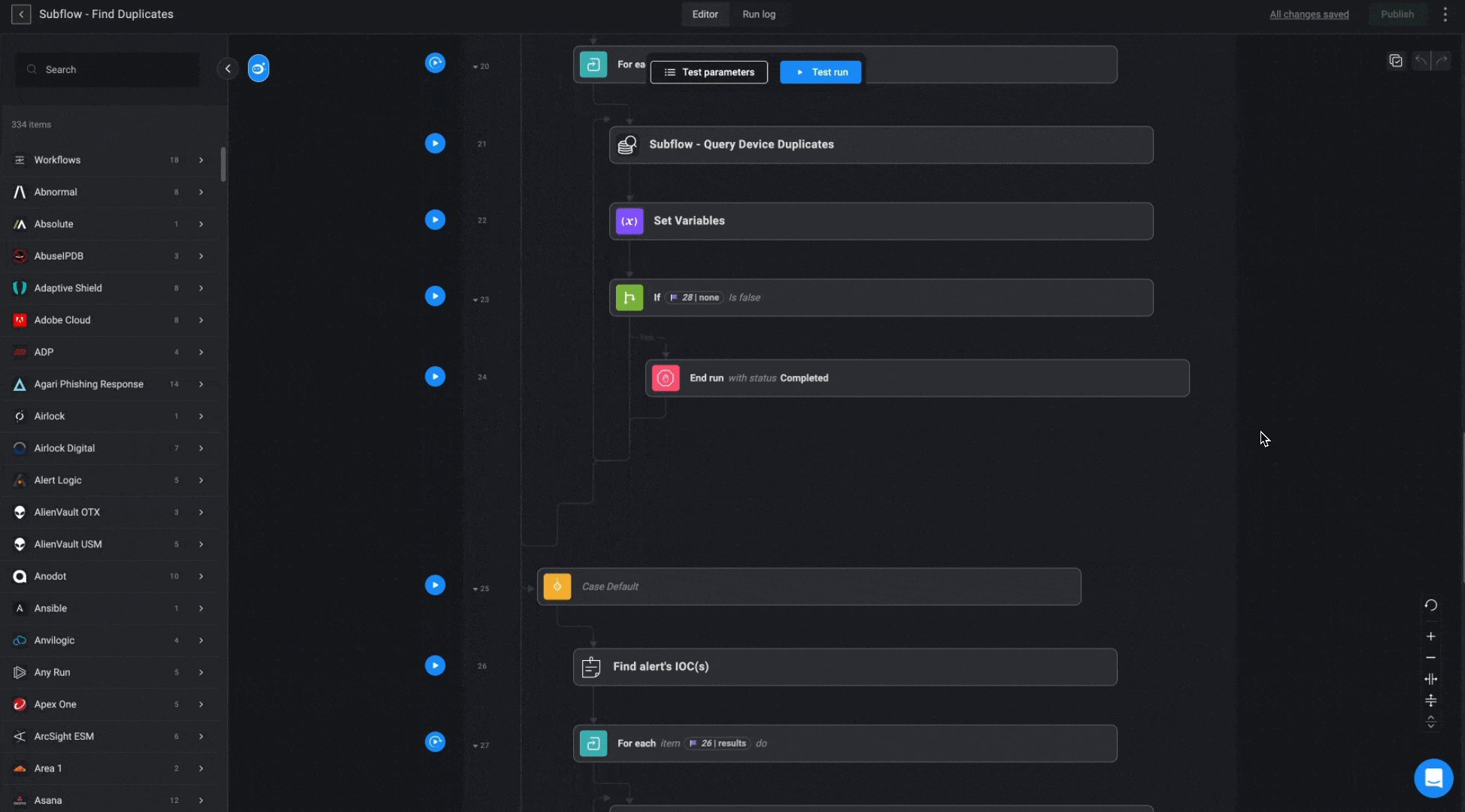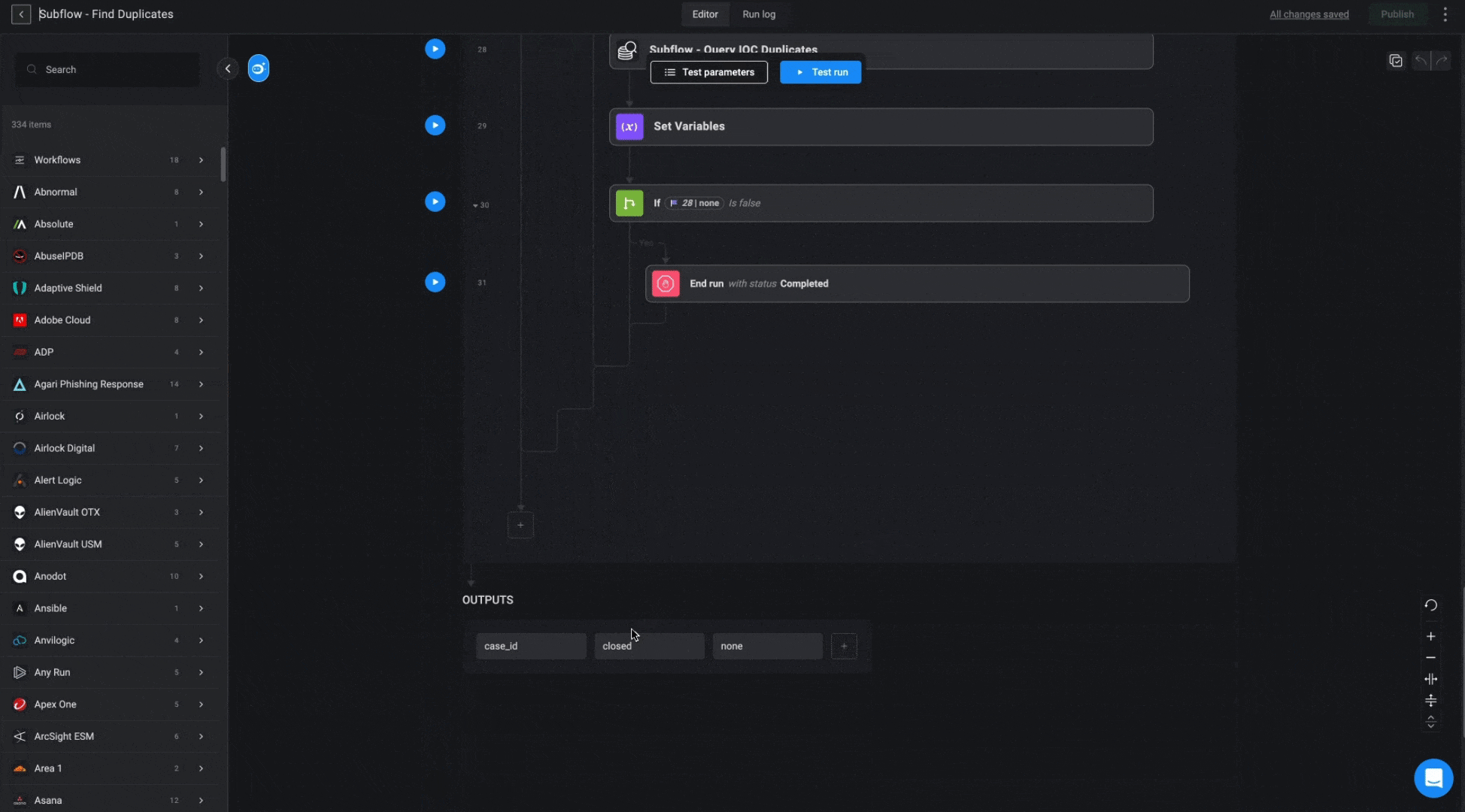
”Query User/Device/IOC Duplicates” Subflows
These subflows apply similar logic across different databases (Users, Devices, and IOCs) to locate related cases. The goal is to find an existing case based on a provided parameter, prioritizing open cases first. If no match is found among open cases, the subflow will search through cases closed within the last 7 days. If multiple matches are found, the most recently updated case will be selected.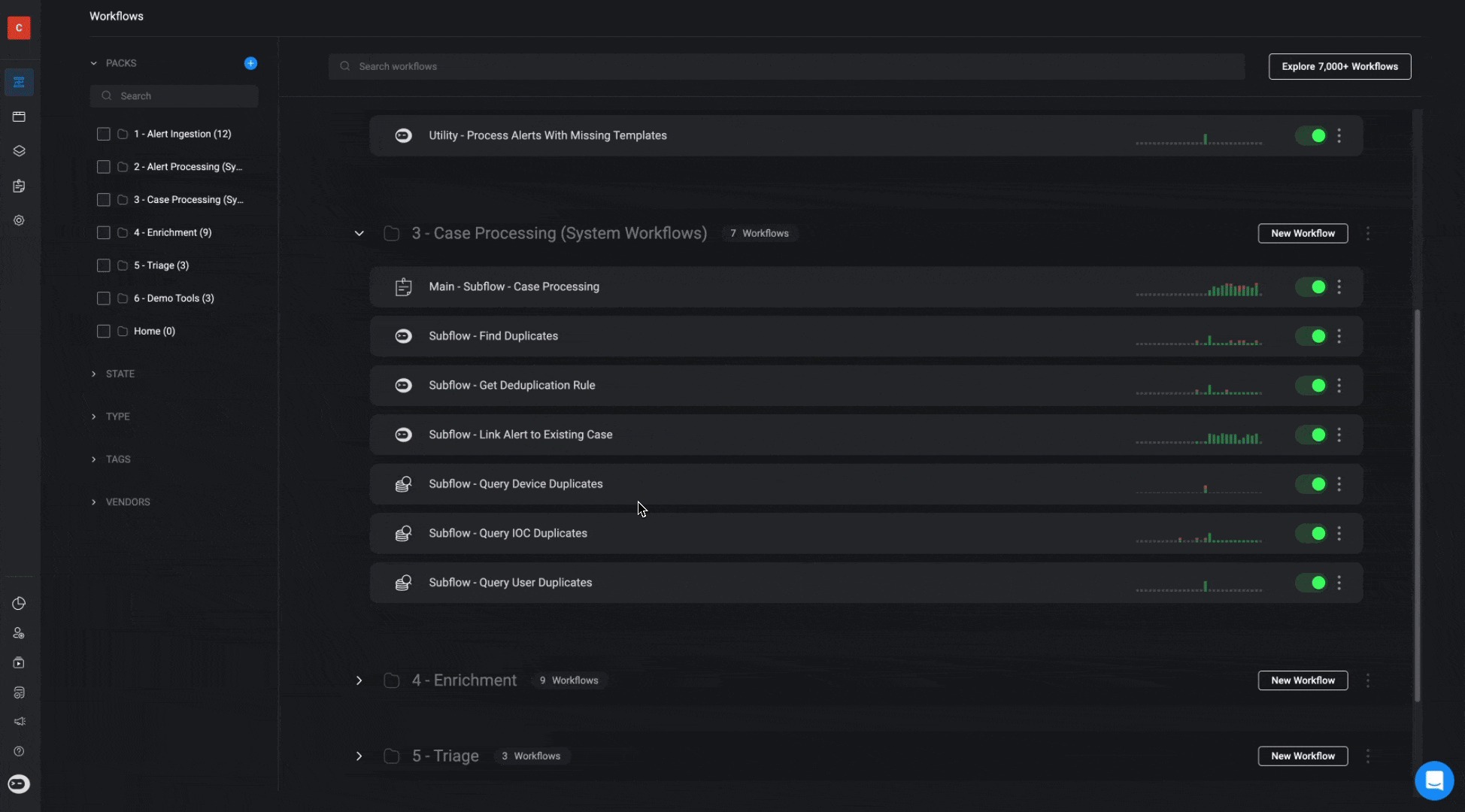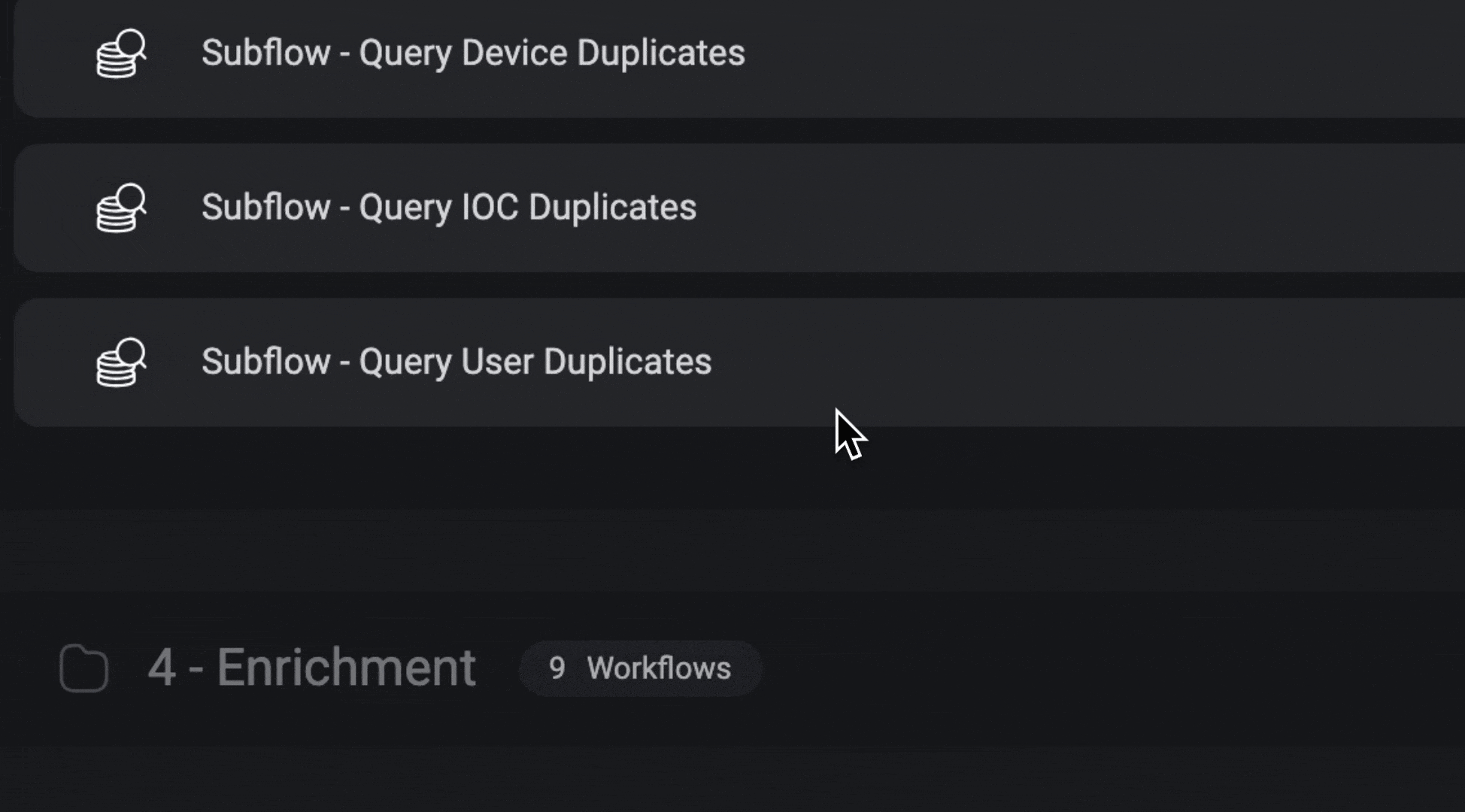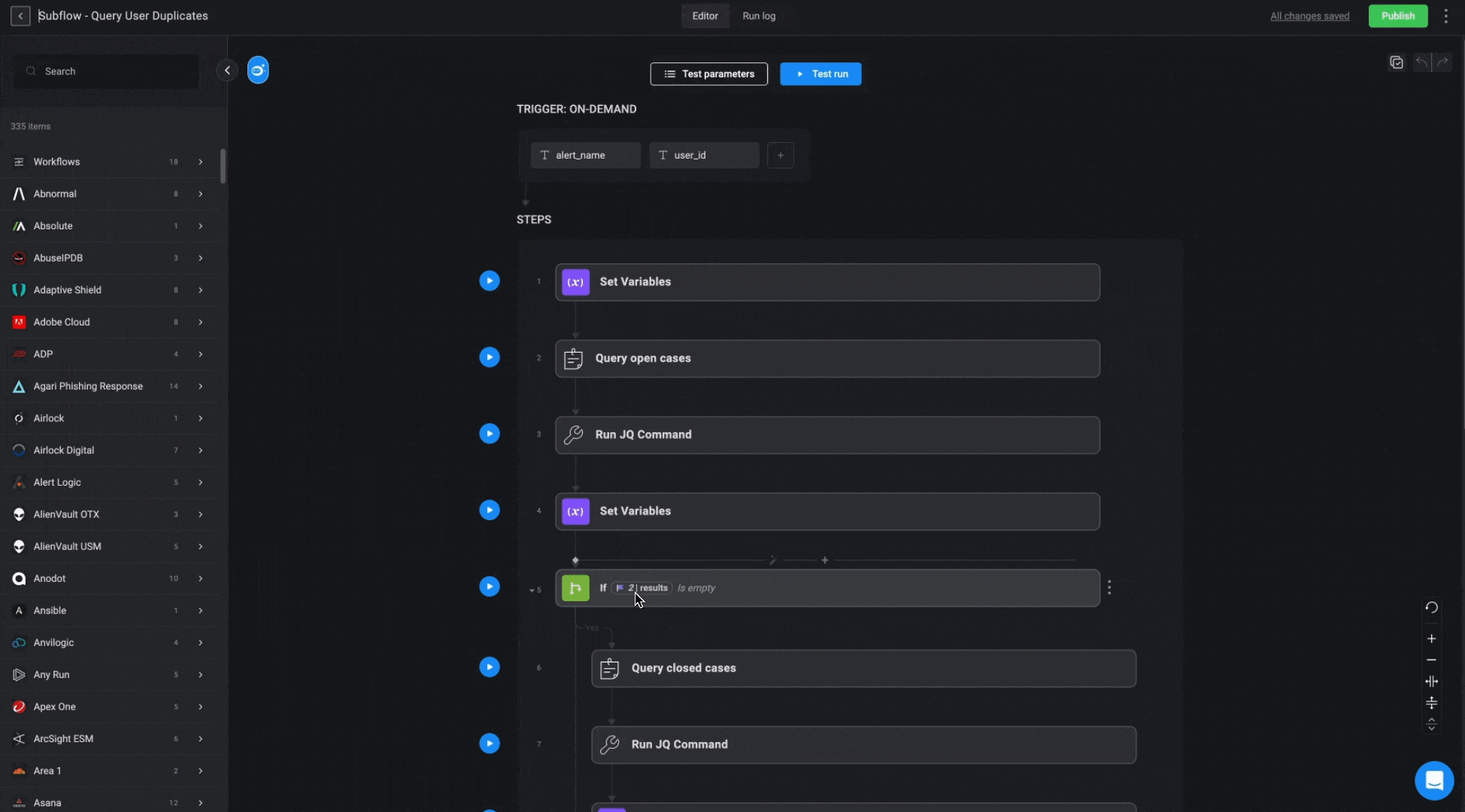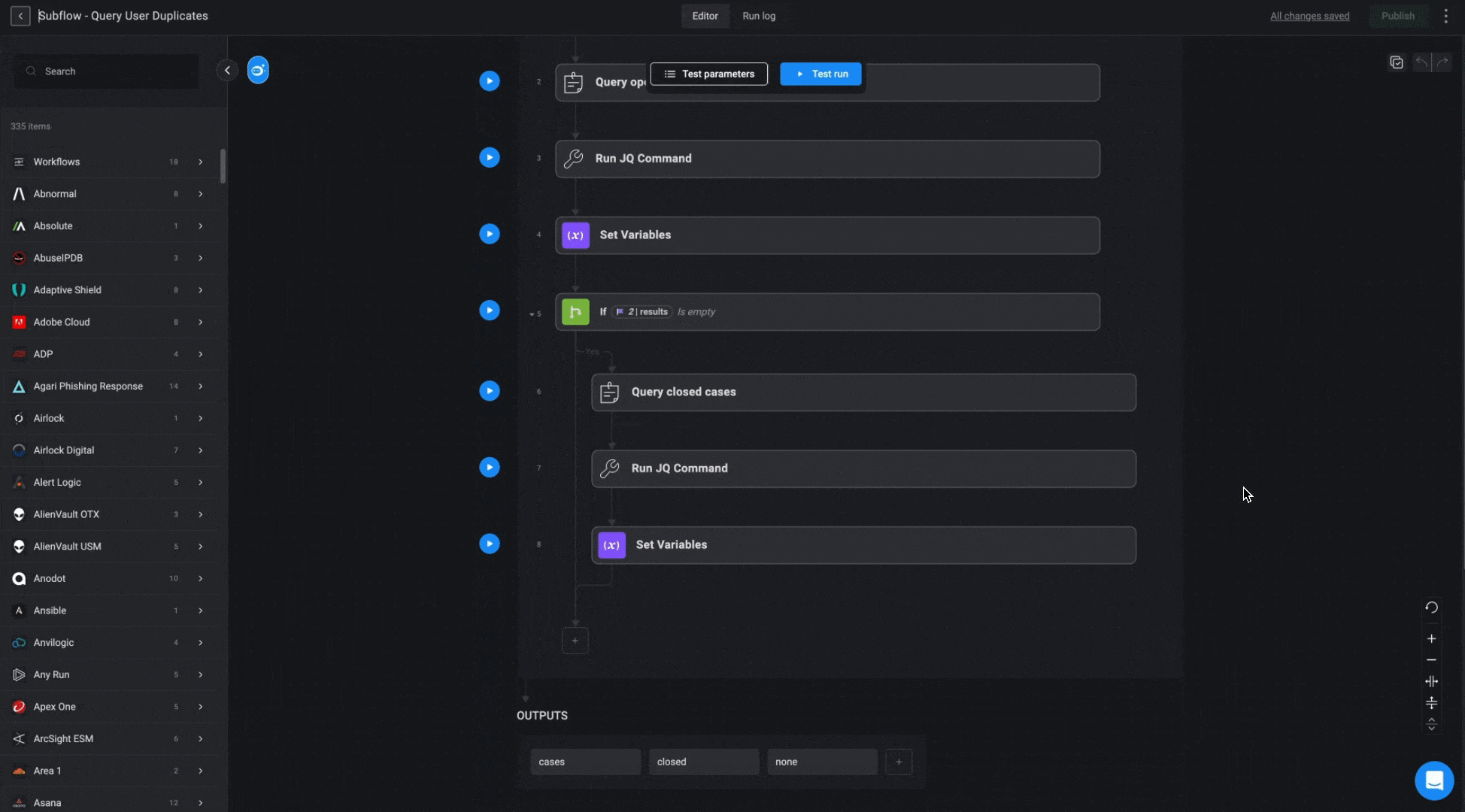
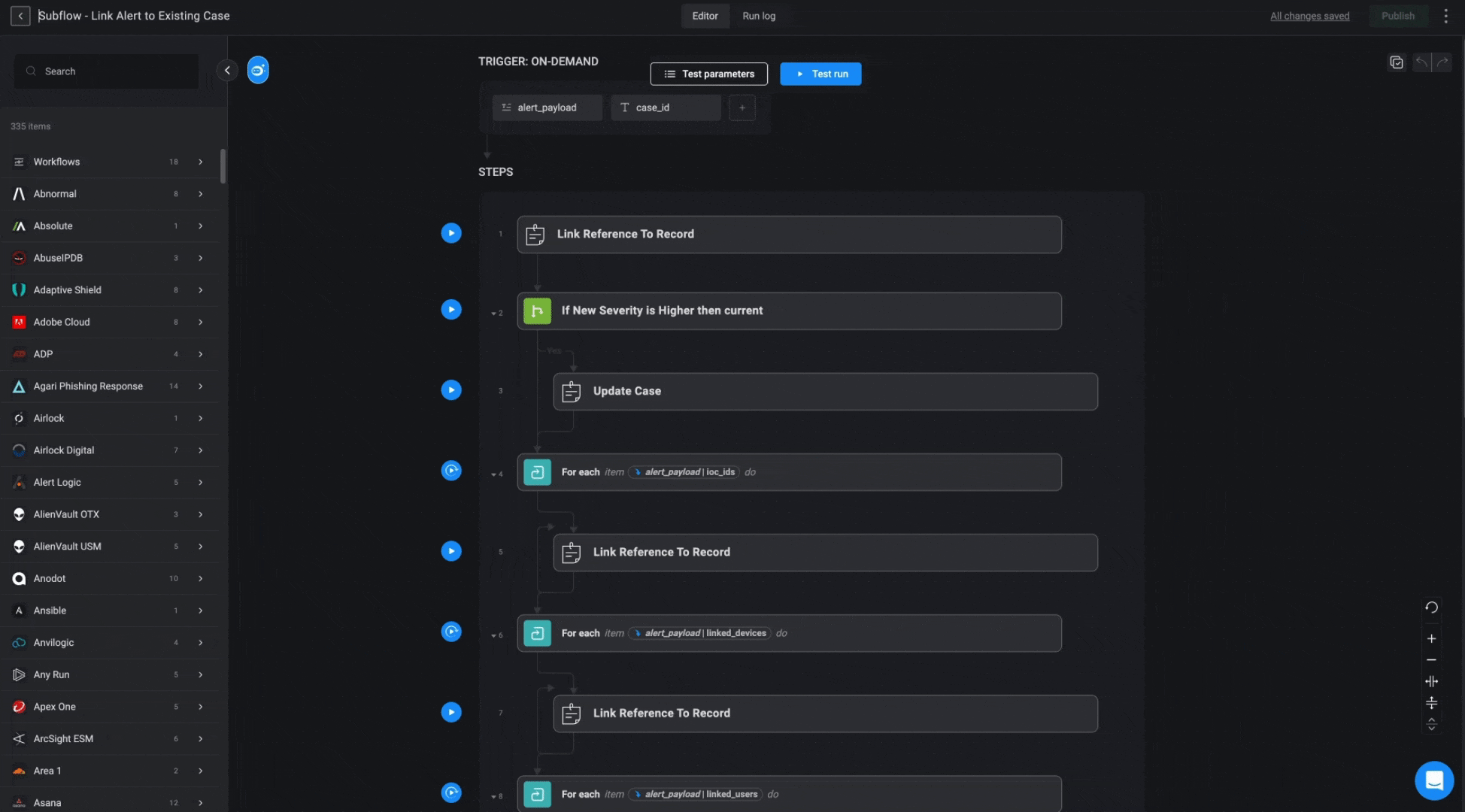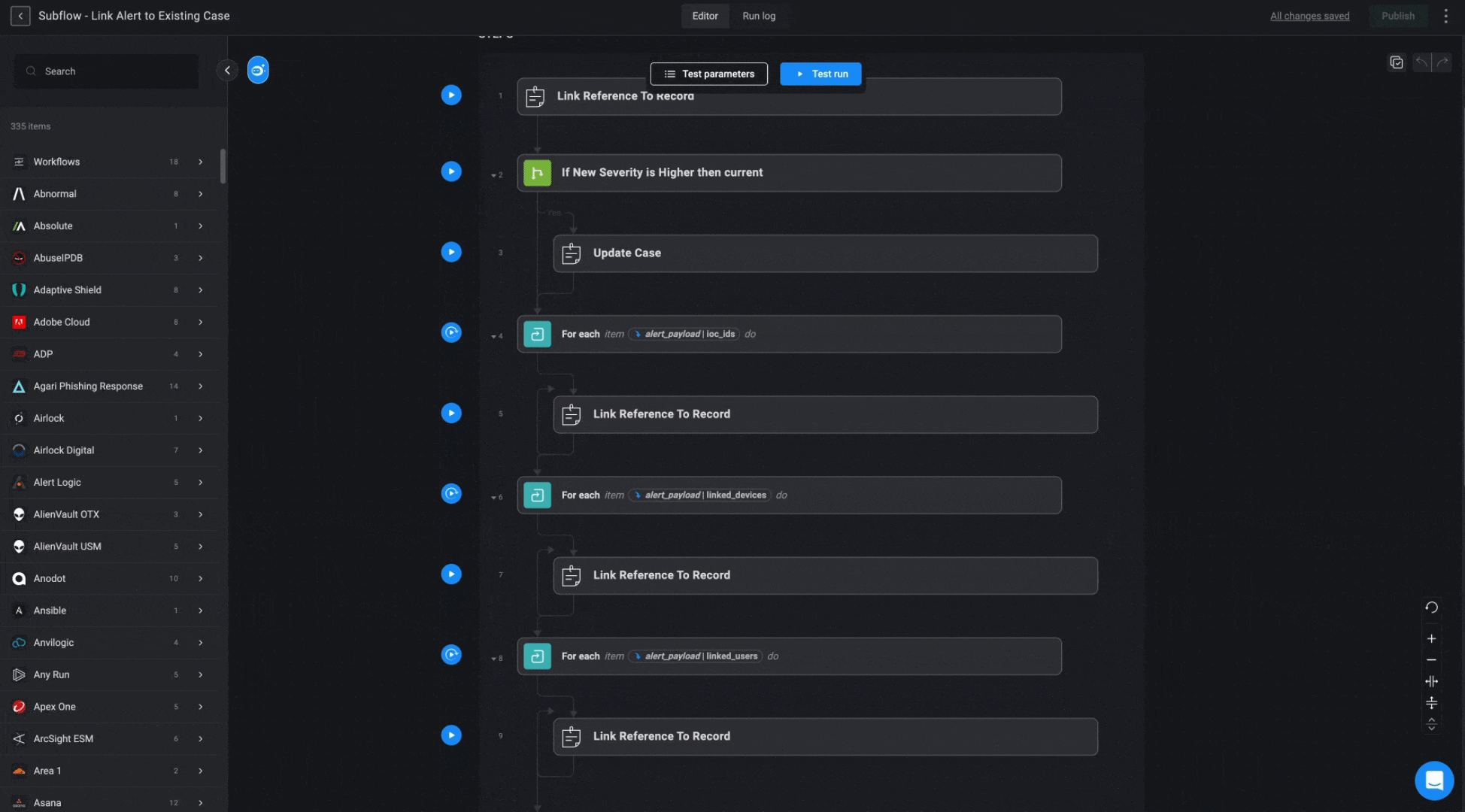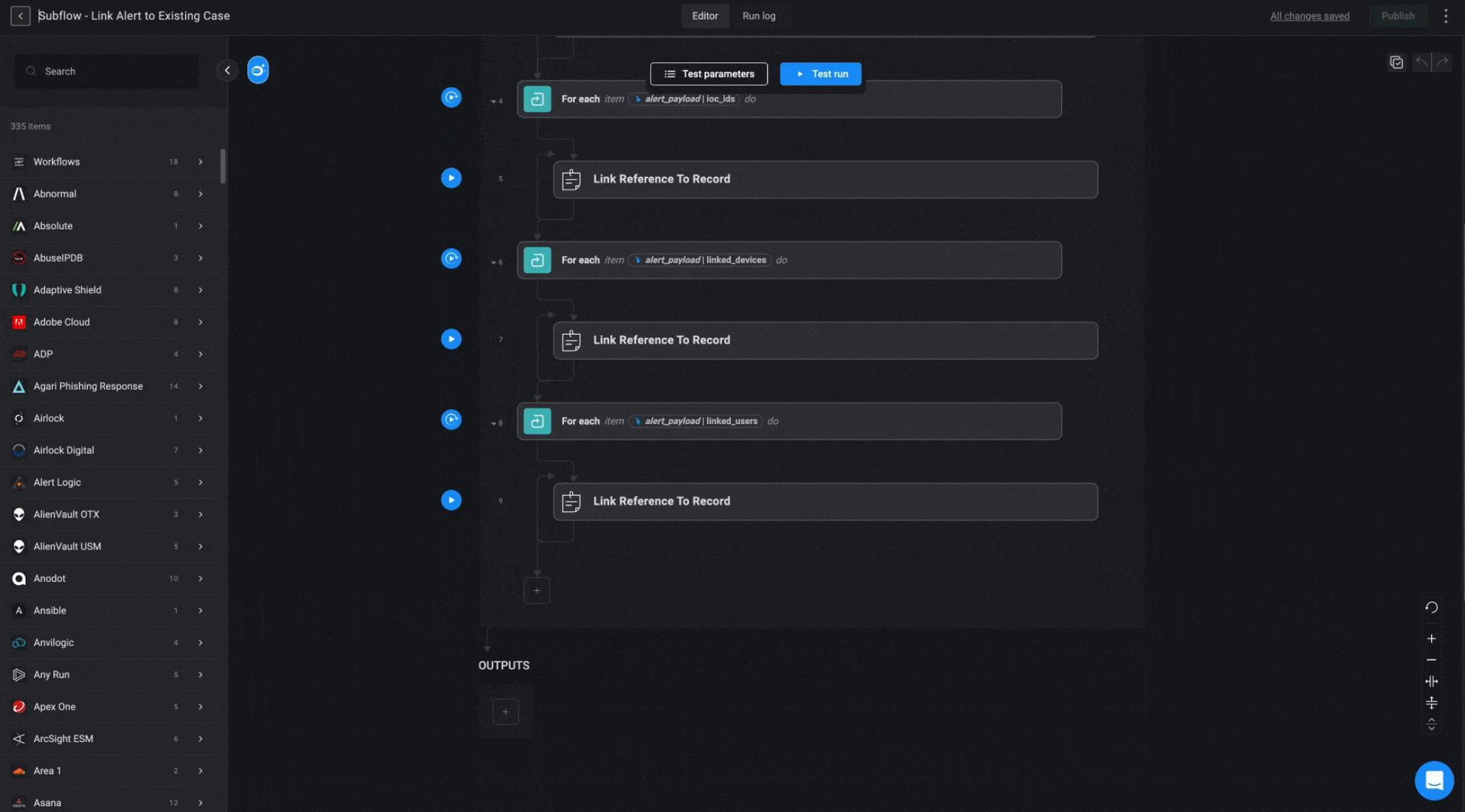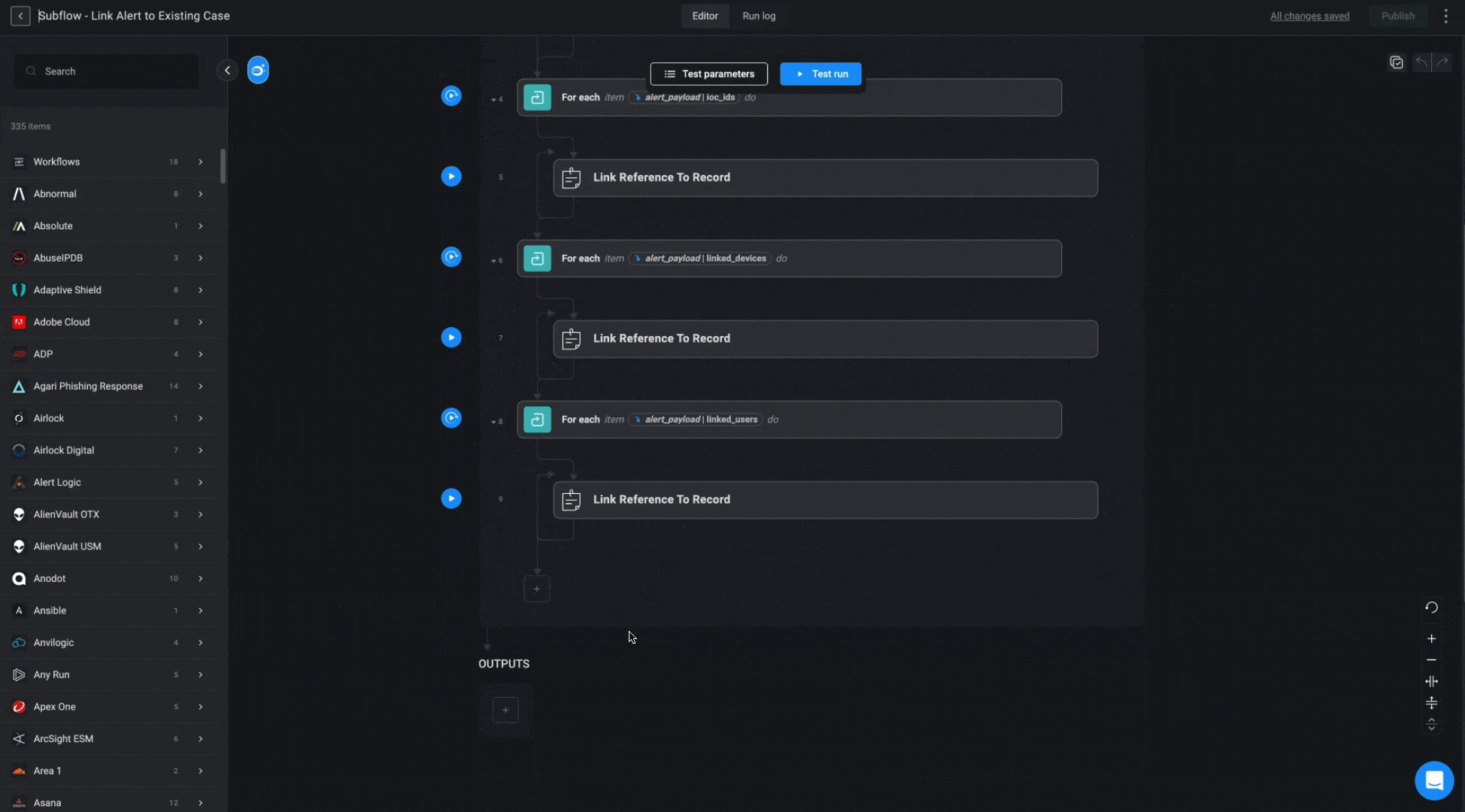
Subflow - Link Alert to Existing Case
This subflow links the alert, along with its associated observables, to the identified case. It also updates the case severity to match the alert’s severity if the alert’s severity is higher.